
From the person who gave you varieties of only part-ones (Angular, Networking), I’m very excited to present the seventh and last blog post of the AWS introduction series!!

Today we will talk about a variety of techniques to use AWS services to meet your needs in the best way, including scalability, automation, and more! Here is a table of content for easy access:

The content of this blog post is based on the course AWS Certified Cloud Practitioner 2020 by a cloud guru and on the whitepapers Well architected framework and AWS overview.
High Availability and Scalability
Let’s start with scalability and see how it connects to high availability.
Scalability means that a system can handle greater loads by adapting. There are two types of scalability: vertical and horizontal (=elasticity).
Vertical Scalability is scaling up/down: Upgrading/downgrading the instance, like getting a new fancy phone. It is common for non-distributed systems, which makes sense because this is when you can not add a machine and split the data.
—
A side note about distributed systems:
A distributed system is a computing environment in which various components are spread across multiple computers on a network. In a non-distributed system, all the parts of the system are in the same physical location.
As I see it, if you need to use the internet to communicate between your components — it’s distributed. That means, that almost all of the systems we know today are distributed, maybe besides some projects you did as a freshman in College.
If you wanna learn more about distributed systems, I stumbled upon the lecture Why are Distributed Systems so hard? A network partition survival guide — Denise Yu and it’s fun and full of cats!
—
Horizontal Scalability is scaling out/in: Adding/ removing instances, like getting extra 3 phones! (identical to your original phone) This one is common for distributed systems, and easier than vertical scaling mainly because there is no hardware limit to reach (you can always add another instance).
High Availability is using different locations and that’s why it goes hand in hand with horizontal scaling. It means running your system in at least 2 distinct data centers (=availability zones), so you can survive a data center loss.

Automation
There are 3 ways to automate in AWS: Serverless management and deployment, infrastructure management and deployment, and lastly — alarms and events.
Serverless Management and Deployment
Ideally, you would like to get everything serverless because then you don’t need to worry about infrastructure. I have to be a geek for a second and mention that “Serverless” is a misnomer (inaccurate name) in the sense that servers are still used by cloud service providers to execute code for developers, but if a server goes down it’s not on you to replace it — all you worry about is deployment.
Infrastructure management and deployment
AWS offers services that will scale automatically, and all you have to worry about is your code. For example:
- Elastic Beanstalk is a service for deploying and scaling web applications and services. The deployment, from capacity provisioning, load balancing, and auto-scaling is done automatically.
- EC2 auto-recovery: Automatic recovery migrates the instance to another hardware during an instance reboot while retaining its instance ID, private IP addresses, Elastic IP addresses, and all instance metadata.
- AWS systems manager, which allows you to safely automate common and repetitive IT operations and management tasks.
- WAF (Web App Firewall) security automation: Automatically deploys a set of AWS WAF rules that filter common web-based attacks.
Alarms and events
This is the first thing that pops into my head when I think about automation. A few AWS examples:
- CloudWatch Metric Alarms: Classic automation, get notified when what you’re waiting for/ afraid of happens, instead of constantly checking.
- Cloudwatch Events: Those are system events that describe changes in Amazon Web Services (AWS) resources. For example, get a lambda function to do something when someone uploaded a picture to your S3 bucket. It’s a way of having your environment proactively respond to events.
- Lambda scheduled events: Schedule events for every defined period of time. For example, run the lambda function at midnight, or every Monday.
Loose Coupling
It’s easier to talk about loose coupling after explaining tight coupling, so let’s start there. Tight coupling means classes and objects are dependent on one another. So, when you change one component it could break your system quickly. With loose coupling, you design independent components, and you increase the flexibility and the resilience of the code.
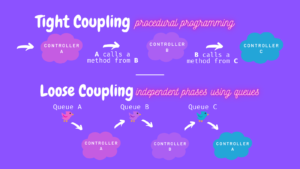
There are three ways to achieve loose coupling:
- Well-defined interfaces: For example, the AWS API gateway allows you to create your own APIs and expose them to the public internet. Interfaces are loosely coupled because the only knowledge that class A has about class B, is what class B has exposed through its interface.
- Service discovery: Amazon ECS services can be configured to use Service Discovery. Service discovery uses AWS Cloud Map API actions to manage HTTP and DNS namespaces for your Amazon ECS services.
- Asynchronous integration: When your components are loosely coupled, you can work with queues, and when one instance fails, for example, another one can come up and pull requests.
Anti-Patterns in DBs
I have a blog post dedicated to various options of databases in AWS, but when speaking of cloud best practices, it’s also important to mention when should you use what.
Relational DBs
Visually, they look similar to excel sheets: Tables, rows, columns, and fields. You interact with your DB using SQL = Structured Query Language.
Just a reminder, AWS’s Relational DB is Amazon RDS (Relational Database Service), and it lets you choose between 6 different DB services, one of them being Amazon’s Aurora.
You should NOT use relational DB when there is no need for joins or complex transactions. For example, If I plan on pulling information per customer (like latest purchases of X), or if the fields between entries are prone to vary (entries have some different fields), non-relational DB is the way to go.
Non-Relational DBs
Non-relational DBs, such as AWS’s dynamo DB, are using NoSQL. Fun fact, NoSQL actually means “not only SQL”, and not “no SQL”.
The difference from relational DB is that the columns in the table can vary, and this will not affect other rows in the DB.
You should NOT use non-relational DB when the work requires joins or complex transactions. By that, I mean queries like “Get the concatenation of fields A and B for every customer whose last name starts with C and purchased in the last D days.”
Data Warehouse
Amazon’s data warehouse is called Redshift. A data warehouse is an information system that stores historical and collective data from single or multiple sources. While the database is designed to record data, the data warehouse is designed to analyze data.
Now, to reach our anti-pattern, we need to introduce two more terms: OLTP vs OLAP. OLTP (OnLine Transaction Processing) pulls the entire row as RDS does, and OLAP (OnLine Analytic Processing) pulls in large numbers of records.
You should NOT use the data warehouse when you want to perform OLTP queries! You should also NOT use a data warehouse when you can use a data lake. What is a data lake? I’m glad you asked!
Data Lake
A data lake is an architectural approach that allows you to store massive amounts of data in a central location so that it’s readily available to be analyzed. Since data can be stored as-is, you do not have to convert it to a predefined schema, and you no longer need to know what questions to ask about your data beforehand.
Data lake vs data warehouse
- Reason for storing data: undefined vs pre-defined.
- Data is left raw until needed vs processed and ready to be queried.
Amazon S3 is a great place to create data lakes, you can use Amazon Athena (serverless interactive query service) and run SQL queries on your data.
Removing Single Points of Failure
A single point of failure refers to one fault or malfunction that can cause an entire system to stop operating. Hopefully, nothing will ever break, but that’s not realistic. The approach here is that when something does break, it does not shut down the whole system.
Here are a few ways to prevent a single point of failure in AWS:
Introducing Redundancy
Redundancy is a system design in which a component is duplicated so if it fails there will be a backup. A good basic example of it is in the AWS infrastructure — Availability Zones!
Availability zones (AZs) consist of one or more discrete data centers, each AZ with its own power, networking, and connectivity, and is housed in separate facilities. Each region has multiple AZs, so if something happens to one of them, it’s far enough from the rest, and they can be used as a backup!
Detect Failure
Introduce a mechanism to detect failure. For example, health checks! Network Load Balancers use active and passive health checks to determine whether a target is available to handle requests. That way you can respond to the event earlier before there is any major impact.
Durable Data Storage
You should always aspire for durable data storage. Amazon S3, for example, is designed to provide 99.999999999% durability of objects over a given year.
99.999999999% (11 nines) durability means that if you store 10,000 objects, on average you may lose one of them every 10 million years or so. Impressive!
Automated Multi Datacenter Resilience
This one is on the list but is a sub-category of the previous one mentioned. S3 achieves its durability by automating backups creation, which is transparent to the user. It’s not the users who made sure to have 3 backups, they just know that he can always (well, almost) reach their data.
S3 is not a DB, it is a simple storage system (kind of like Google Drive). A more specific example of automated multi-data center resilience is Amazon Aurora. This is Amazon’s in-house DB service, and it stores copies of the data in a DB cluster across multiple Availability Zones in a single AWS Region.
Fault Isolation
Fault Isolation means isolating the component, device, or software module causing the error. This topic connects beautifully to the scaling and high availability we talked about prior! More specifically, horizontal scaling — adding more instances.
Sharding
Sharding, also known as horizontal partitioning, is a popular scale-out approach for relational databases. Amazon RDS provides great features to make sharding easy to use in the cloud.
Sharding increases redundancy both because each shard is a replica set, and because even if an entire shard becomes unavailable, the database as a whole still remains partially functional, with part of the schema on different shards.
Optimizing Costs
There is a dedicated blog post for Billing & Pricing in AWS, but here we’ll emphasize the best practices for optimizing costs:
Right-Sizing
Right-sizing is the most effective way to control cloud costs. Examples of size options in AWS services are:
- EC2 instance types, various combinations of CPU, memory, and network capacity
- S3 storage classes, depending on the frequency of access
- RDS instance type, also various combinations of CPU, memory, and network capacity
Elasticity
Elasticity is the ability to fit the resources needed to cope with loads dynamically usually in relation to scale out. It sounds very similar to scalability, right? So I went to check the difference!
Scalability is being capable to expend for a little additional cost, more of a long-term. For example, using a template. That way, the creation of the template itself will require some work, but adding a new instance using that template will be quicker than creating every new instance from scratch.
Elasticity, on the other hand, is supporting short-term changes, like your stomach getting bigger when you eat, and smaller after a few hours. If you insist on a cloud example, it’s like adding another server to receive requests, for the period when people go Christmas shopping.
Elasticity optimizes costs because you can grow or shrink capacity for CPU, memory, and storage resources to adapt to the changing demands, without long-term commitments and contracts!
Purchasing Options
The third way to optimize costs is by taking advantage of the variety of purchasing options in AWS! For example, Amazon EC2 Instances have four purchasing options: On-Demand Instances, Reserved Instances, Spot Instances, and Savings Plans. Each one is best for different scenarios.
Using Cache
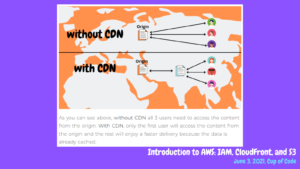
Caching helps us serve data faster and with lower latency. There are two types of caching: App caching and edge caching.
- App caching: Apps can load faster by keeping temporary files such as thumbnails, scripts, and video snippets on your phone instead of loading them from the web each time. In AWS, Elasticache is a web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud.
- Edge caching: This is the practice of using intermediate storage between data centers and end users accessing the resource. In AWS, Amazon CloudFront is a fast content delivery network (CDN) service that securely delivers content to customers globally with low latency and high transfer speeds.
Security Best Practices
Here we will touch on security in a nutshell, and I recommend reading my AWS security dedicated blog post for more coverage. Let’s go over AWS’s security best practices:
- Use AWS features for defense-in-depth: Defense in depth is a strategy that leverages multiple security measures to protect an organization’s assets. The thinking is that if one line of defense is compromised, additional layers exist as a backup to ensure that threats are stopped along the way. AWS provides security features including IAM, firewalls (WAF), port filtering (security groups), and network protection.
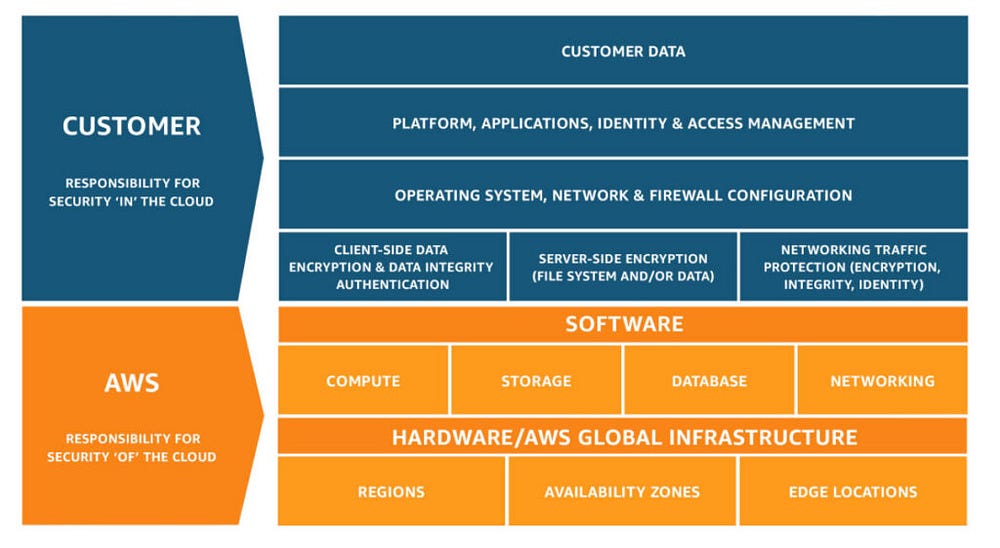
- Share security responsibility with AWS: Security and Compliance are a shared responsibility between AWS and the customer. This differentiation of responsibility is commonly referred to as Security of the Cloud versus Security in the Cloud. The best practice will be for the customer to do their part.
- Reduce privileged access: Users need to get only the access they need. Every user, role, or group shouldn’t have full access to resources and actions, just enough privileges in order to do their job.
- Security as code: Codify your security by creating a golden environment, for example, an EC2 launch template with security patches. That way, every new EC2 instance will be created from that template and therefore be more secure than a basic EC2 instance.
- Real-time auditing: An audit gives you an opportunity to remove unneeded IAM users, roles, groups, and policies, and to make sure that your users and software have only the permissions that are required. Examples of auditing services in AWS are AWS inspector and CloudTrail.
That’s it! Today we talked about best practices in the cloud, and this was the last blog post in the introduction to AWS series.
Now with this one behind us, all that’s left is to practice and take the AWS cloud practitioner exam. Best of luck to all of us! 😀







