As you might know, I’ve recently written a Taylor Swift-themed Wordle game in React. To focus on the game logic, I downloaded a Taylor Swift data set from the Internet. Sounds good, right?
I integrated this data set into the project and happily continued coding. Suddenly, I realized that the song I was currently listening to wasn’t on the list! This means that the list was too old (or that Tay-Tay is releasing new albums at a rapid rate). Right then and there I decided that I could trust no one — and should create my own data set!
Not only that, but I saw here a good opportunity to get hands-on experience with Spotify API :D.
So, what is on the agenda today?
- Requirements
What data do I need for my Wordle game? - Theoretical
Because we came here to learn! - Connecting to Spotify API + Performing API calls
And important things to notice! - Data Processing
With all due respect to Taylor’s Version, of course. - Modifications for future use
How to update the data set without running everything again.
Shall we begin?
Requirements
I wrote a Wordle game themed with Taylor Swift song titles. To accommodate that, I am interested in a JSON file containing information about all Taylor Swift songs, with these restrictions:
- No duplicates: This is a requirement that the queen made very challenging with her album re-recordings.
- Song titles no longer than 13 characters: This is so I have a reasonable amount of characters to present in a word-guessing game. Six tries are probably not enough to guess “We Are Never Ever Getting Back Together”, not to mention the width of a mobile view!
- Every object needs to have a
splitarray: This array would indicate after which indexes there were spaces, in a space-less string of the song title. For example,“shakeitoff”-> [4,6]because:
Shake it off
01234 56 789
- Every object needs to have an
album_titleproperty, to let the user of the game know where they can find this song. - The list has to be shuffled because we don’t want a guessing game such as Wordle to have a pattern in the solutions!
Why JSON and not CSV?
JSON is JavaScript Object Notation, and CSV stands for Comma Separated Values. Both are great ways to save data, and each has its advantages.
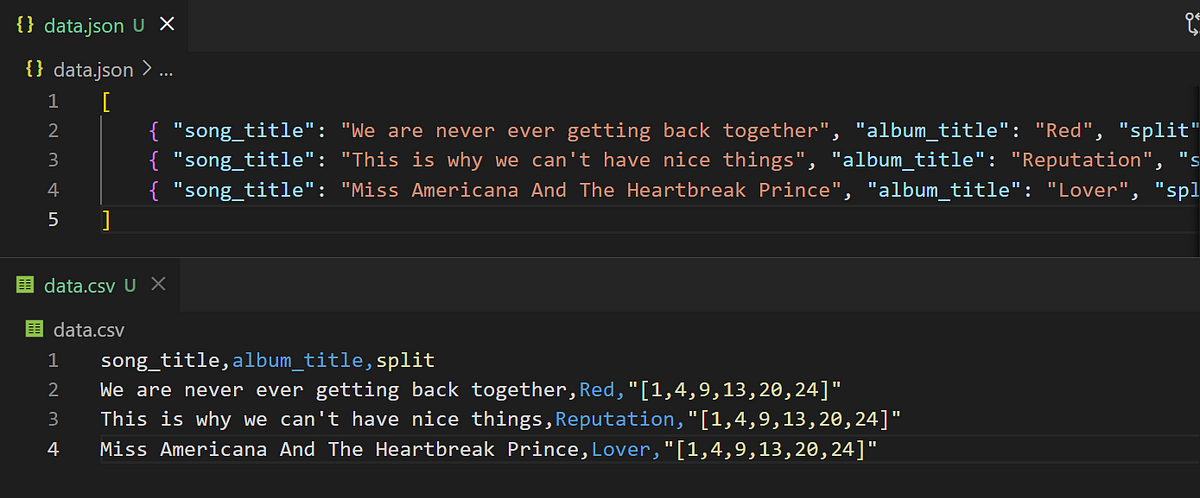
In the screenshot above you can see dataset examples I made to show you the difference between the formats’ syntax. Note that CSV, as the name implies, is sensitive to commas, so you’ll need to wrap every comma-containing string in your data with quotation marks (the split array is a good example of that). On the other hand, everything is wrapped in quotation marks in JSON files.
In my case, the data is pretty simple (string, string, and a short array) and both formats will do the job. I chose JSON because I wanted this data set file to be reachable from outside the game. That way, when I update the file I don’t need to redeploy the game. JSON is the recommended way for communication between web applications and APIs.
Theoretical
We’ll start with the new terms we touch on in this blog post.
If you read the Spotify for developers documentation, you’ll see that “Spotify implements the OAuth 2.0 authorization framework”. What is OAuth 2.0?
OAuth 2.0
OAuth 2.0, which stands for “Open Authorization”, is a standard designed to allow a website or application to access resources hosted by other web apps on behalf of a user. (source)
A nice analogy for this is a coffee shop restroom. In some restaurants, there is a code on the bathroom door you can get only if you buy with the cashier. The code is printed on the receipt and is replaced daily. The restaurant does this to authorize only the paying customers to use the restroom.

This approach is similar to OAuth 2.0. The customer has the access they need, but it’s the owner of the service who withdraws the access every day (and changes the code). If, for example, the access to the restroom would have been done with a key, it’s the key holder that has the access. With a key to control access, customers come to the cashier and ask for the key, use it, and then return the key. A customer with a key has access that can not be revoked (not as quickly and easily as a code).
When looking at Spotify, as you will soon see, we won’t be getting any permanent password to access the data. Instead, we receive an access token that gives us temporary access.
Access Token
In general, there are two types of information you can pull from Spotify: General data (artists, albums, songs) and user-specific data (liked songs, “for you” playlists, etc). We want the first category — which is what Spotify calls Client credentials workflow.

Our application will be requesting the Spotify accounts service for an access token. With that access token, we will make requests to Spotify Web API. Note that there are two players here: Spotify accounts service is the coffee shop cashier and Spotify Web API is the restroom 😉
The response from the Spotify accounts service is returned in this format:
{
"access_token": "NgCXRKc...MzYjw",
"token_type": "bearer",
"expires_in": 3600
}
This means that we can use this token in the next hour, with the bearer token type. What is this bearer?
Bearer Authentication
Bearer authentication (also called token authentication) is an HTTP authentication scheme that involves security tokens called bearer tokens.
The name “Bearer authentication” can be understood as “give access to the bearer of this token”. The client must send this token in the Authorization header when making requests to protected resources. (source)
This means that when we build our request to Spotify API, we will need to add a header of authorization, using the word “Bearer” and attach the access token: {“Authorization”: “Bearer “ + access_token}.

Let’s see it in the code!
Connecting to Spotify API
Getting The Access Token
You might’ve noticed in the Client credentials workflow above that to get an access token, we need client_id and client_secret values. The client in this case is a Spotify project. Therefore, the first thing you need is to create a Spotify project/application in developer.spotify.com:
- Log into your account. It is the same as your “regular” Spotify account.
- Go to the dashboard and Create a new project. This is the configuration I used:
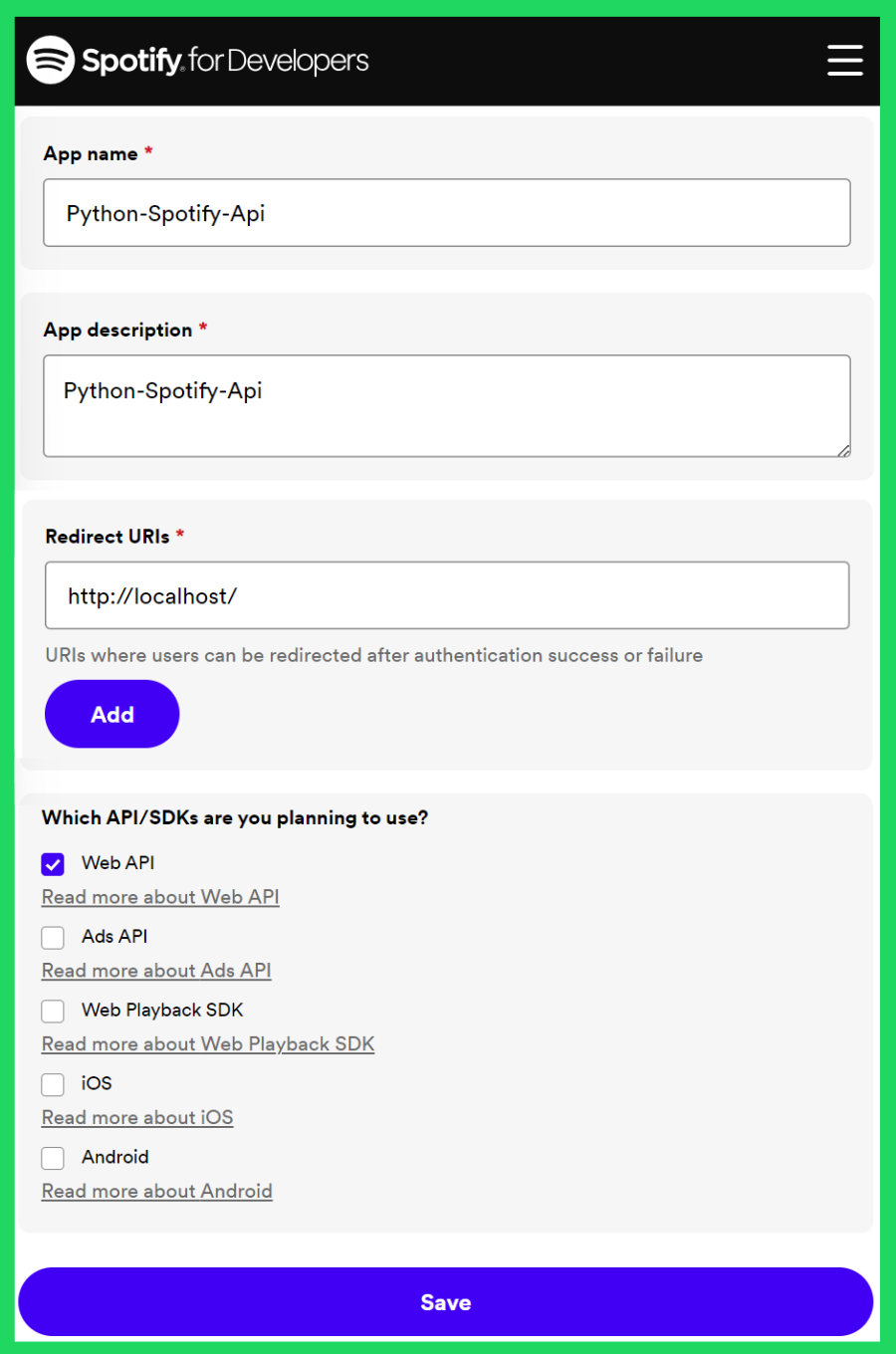
- Click Save.
- Under Settings, You will find your
Client IDandClient Secret. Grab those and open the VS code! (or another IDE of your choice)
Using the Access Token
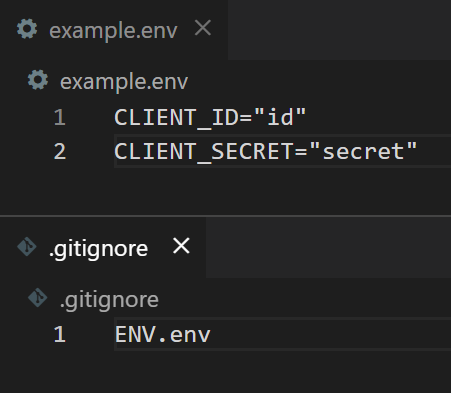
We will start by saving the client variables in the ENV.env file. I suggest you also create example.env and .gitignore files now so you won’t accidentally upload your client secret to GitHub!
Let’s go back to the IDE. We’ll start by importing the environment variables:
Now we need to create the request in a very specific structure. We’ll do it exactly as the documentation says:
– Send a
POSTrequest to the/api/tokenendpoint.
– grant_type: Set it toclient_credentials.
– Authorization: Basic <base64 encoded client_id:client_secret>,
– Content-Type: set toapplication/x-www-form-urlencoded.
- On line 18 we are sending a
Postrequest to the/api/tokenendpoint. We can see this endpoint in the code on line 12. - We set
grant_typetoclient_credentialson line 17. - We create the header with authorization and content type on lines 13–16. To create
<base64 encoded client_id:client_secret>string, we first create the stringclient_id:client_secreton line 10, then we encode it in base 64 on line 11. - Lastly, we decode the JSON data on line 19.
This looks good but it’s not working yet.
If you run this (with py ./main.py in the terminal), you’ll get the following error:
TypeError: a bytes-like object is required, not ‘str’. This error arises while trying to encode to base64 (base64.b64encode(client_id_and_secret)). This means we need to encode client_id_and_secret to be in bytes, not in string. The solution is to add a “translation“ to bytes between lines 10-11 above:
client_id_and_secret = client_id + ":" + client_secret
client_id_and_secret_bytes = client_id_and_secret.encode("utf-8")
client_id_and_secret_base64 = base64.b64encode(client_id_and_secret_bytes)
After doing that, we reach the next error: TypeError: can only concatenate str (not “bytes”) to str”. When we try to compose the authorization string (“Basic “ + client_id_and_secret_base64). Now the problem is that we don’t have a string!
There is an easy fix for that: Wrap our client_id_and_secret_base64 with str(...).
Cool, now it runs! But hey, the result isn’t the JSON we expected: {‘error’: ‘invalid_client’}. Another bug! Looks like there is a problem with the client ID and secret we send. I test it by printing: print(“Basic “ + str(client_id_and_secret_base64)) and I see Basic b’MjY5N…’ . Wait, where did this b'..' came from?
Bytes literals are always prefixed with ‘b’ or ‘B’; they produce an instance of the bytes type instead of the str type. (source)
This means we are stringifying the object, but not accurately enough (‘A’ != b’A’). For the Authorization header, we want a UTF-8 string — so we need to specify that: str(...,"utf-8")
Now it works! Note that we need to extract the access_token from the JSON (line 20 below):
Performing API Calls
Now that we have the access token, we can make API calls! But which APIs do we need?
In my project, I want all of Taylor Swift’s songs. After looking at the documentation, it looks like my script should do the following calls:
- Search for Tay-tay’s artist ID
- With that ID, get artist’s albums
- For each album, get the album’s tracks
Cool! I’m ready, are you ready?
GET Artist ID
I played with the “try it” tool on the website and got this:
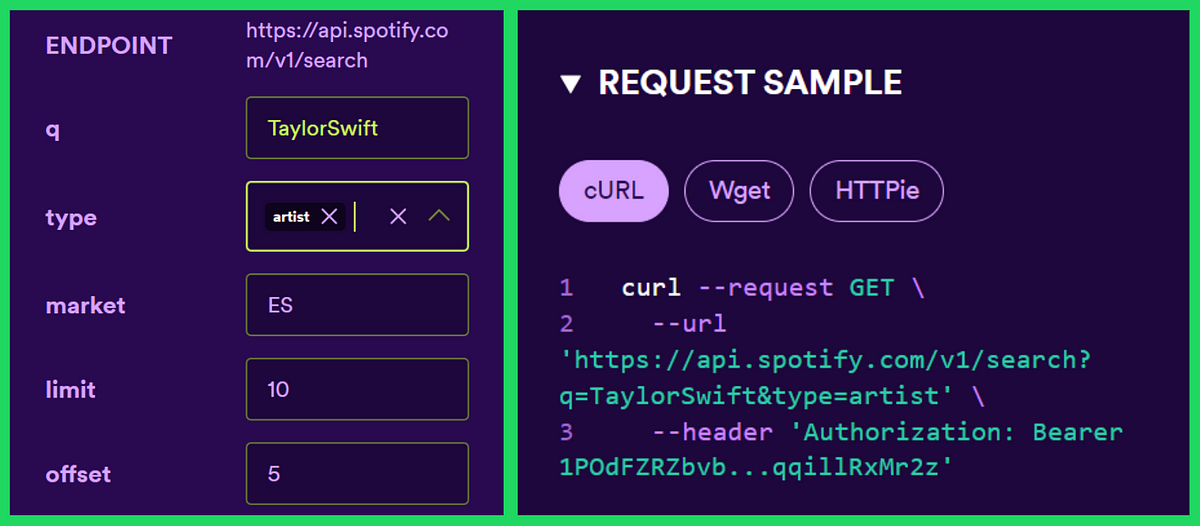
Let’s implement something similar in our code:
Looks like we need two variables to create a GET request: URL and header. We saw those two in the POST request above (result = post(url, headers=headers, data=data)).
- We’ll write the URL similar to the one in the tool:
https://api.spotify.com/v1/search?q=TaylorSwift&type=artist - The header has bearer authorization, using the access token from the previous function:
{“Authorization”: “Bearer “ + token} - Lastly, we need to pass the token as a parameter. I decided to pass the artist’s name as well, to keep the function more generic: What if one day I’ll get sick of Taylor Swift? JOKING! I will never.
Our function will look like this:
Let’s look at the result we got:
Notice there are 13 Spotify artists with “Taylor Swift” in their name (`total`: 13 on line 10), but there is only one Queen T! Therefore, limiting the result items to be of size 1 will get us the ID we need:
- Add
&limit=1to the end of the URL. - Extract the
idproperty by usingjson_result[“artists”][“items”][0][“id”].
Now that we have the ID, we don’t need to perform this call anymore. Our main code will look like this:
...
# main
TAYLOR_SWIFT_ARTIST_ID = "06HL4z0CvFAxyc27GXpf02"
access_token = get_access_token('ENV.env')
artist_id = TAYLOR_SWIFT_ARTIST_ID # get_artist_id(access_token, "Taylor Swift")
GET Artist Albums
Now that we understand how an API call works, let’s look at the next one because it has a complexity we didn’t need to think about before: There is only one Taylor Swift, but there are multiple albums!
We’ll start with a simple scenario:
When you run this code, you’ll see the result you get is pretty big for the human eye and includes a lot of information we don’t need. As much as it is tempting to do processing here, let’s keep this function true to its name — getting the albums from Spotify. Therefore, we will just return return json_result[“items”].
The next step is to create a dictionary of album names to album IDs:
The reason I’m grabbing both name and id is because the name is used in my data set, and the id is used later to grab the album tracks!
Running this code shows that this small amount of processing resulted in a much smaller JSON:
Wait. This list is too small – it does not contain all the albums! Any guess why is that? Let’s look at the fields of the response we got:
We sent a short and sweet URL (https://api.spotify.com/v1/artists/{artist_id}/albums), and on lines 2–3 above it looks like the URL has some default fields that affect our response:
?include_groups=album,single,compilation,appears_on&offset=0&limit=20
- According to the documentation, we can filter the response to include only studio albums:
.../albums?include_groups=album. That will drastically lower that'total':387on line 10! - The limit is the maximum number of items to return (line 5). The default is 20, the minimum is 1 and the maximum is 50. Let’s do 50, shall we?
- The offset is the index of the first item to return (line 8). The default is 0, which means we start with the first item. We don’t need to touch this one.
With all that new information, our new URL will be: https://api.spotify.com/v1/artists/{artist_id}/albums?limit=50&include_groups=album, and the response coming back is:
Therefore, the output of create_album_name_to_id_dict() is:
GET Album Tracks
Like with the albums, we’ll start with a simple call:
Given an album id, we pull the tracks. In a separate function we’ll create a song-to-album dictionary:
We will loop over these functions for each album in the album_name_to_id dictionary and the result will be:
{
"Welcome To New York (Taylor's Version)": "1989 (Taylor's Version)",
...
"Teardrops on My Guitar - Pop Version": "Taylor Swift"
}
(332 songs, the full list can be found here).
This wraps up the section of the API calls. Next, we will start processing the data, which might require us to come back for some adjustments.
Before we do that, let’s make sure we are on the same page regarding main.py:
Data processing
Remove Special characters
If you peek at the songs we gathered, you will see some song titles that are not Wordle-ready. Wordle solutions should not have special characters like commas, parentheses, single quotation marks, and digits.
Because of that, we need to create a function that removes those characters. Hey, do you know what would be a fun way to do that? Test-driven development!
We’ll start by exporting song_to_album into a file.
...
song_to_album.update(songs_to_one_album)
data_json_format = json.dumps(song_to_album)
file = open("song_to_album.json", "w")
file.writelines(data_json_format)
file.close()
Then, we’ll create a name-processing function and run the names through that function. After that, we’ll loop over the list with another function checking if the names are alphabetic, and print the remaining “bad ones”.
That way, we’ll adjust our name-processing function until all the names are valid!
- On lines 4–6, we open the file and save the JSON object in a variable.
- On line 9 we loop over the songs (the keys of the dictionary) and on line 10 we call the processing function. We start with this function empty.
- On line 11 we check if the song name without spaces is alphabetic. If not, we print that name.
This is our starting point:
wordlestruck-spotify-api> py -m src.test_process_name_func
Welcome To New York (Taylor's Version)
...
"Slut!" (Taylor's Version) (From The Vault)
...
Is It Over Now? (Taylor's Version) (From The Vault)
Anti-Hero
You're On Your Own, Kid
Question...?
...
the lakes - bonus track
Miss Americana & The Heartbreak Prince
Soon You’ll Get Better
ME!
...
---
190 songs
Looks like we have 190 song titles to fix! Don’t worry, this amount will drop pretty quickly.
At this point, you might wonder why we are “wasting time” on all song titles, instead of working on the ones that are no longer than 13 characters. This is because we have to “clean” the song titles to know which are in the correct length.
Let’s start writing the function!
With all due respect to Taylor’s version, we’ll start by trimming the parenthesis. It doesn’t matter if it’s round or square — we don’t need it in our Wordle solution. I created a dedicated function for this part:
We are down to 95 song titles to fix!
The next thing that pops up in the output is the suffix after the “-“ character. Let’s add code for that:
def process_name(name):
...
index_of_hyphen = name.find(" - ")
if(index_of_hyphen > 0):
name = name[:index_of_hyphen]
Now we are down to 43 “bad” songs! At this point you might notice some duplicates — this is ok, we have a dedicated section for that later.
The next step is to start using the replace function! The first replacement will be of the single quote character, on all its varies:
name = name.replace("'", "").replace("’", "").replace("‘", "")
This brought us down to 24 “bad” songs!
The next character to remove is “…” but note that we can’t just remove it because it might function as a separation between words (Come Back…Be Here). So, we replace it with white space. This means the other songs in this group will have a trailing whitespace, which we will resolve with .strip().
def process_name(name):
...
name = name.replace("...", " ")
return name.strip()
- Now I’ll add the replacement for the characters
?/!/,/.which will resolve for us another 9 songs! NOTE that this should be added after the...trimming. - Next, we will replace
1withone,22withtwenty twoand&withand.
wordlestruck-spotify-api> py -m src.test_process_name_func
"Slut"
Anti-Hero
Back To December/Apologize/Youre Not Sorry
---
3 songs
The last thing to do is remove the double quotes and the -. Note the difference between - in a song name like Anti-Hero and the one trailing a song name (the lakes — bonus track). The trailing one is padded by whitespaces, and we do it before!
I’m ignoring the song title Back To December/Apologize/Youre Not Sorry because it is definitely longer than 13 characters.
That’s it! This is our final function:
At this point, we have a beautiful name-processing function, but we haven’t called it yet!
We’ll go to where we create the song_to_album dictionary, and add 2 things: First, process the name. Then, if the name is no more than 13 characters — add it to the dictionary!
Make sure you use the processed name as the key!
The new song_to_album list can be found here.
{
"Blank Space": "1989",
...
"New Romantics": "1989 (Deluxe)",
"Slut": "1989 (Taylor's Version)",
...
}
I like that there is a difference between the original album, the deluxe version, and the new songs from the vault. If you don’t like it, you are now fully capable of trimming the album titles 🙂
It’s important to mention that the list isn’t final! But it’s good enough for this stage of the project. After we finish coding the simple version, we’ll come back and fine-tune the code. Don’t worry, you’ll leave this blog post with a full end-to-end project!
The Split Array
For the wordle game, each song should have 4 fields: id, song_title, album_title, and split array. We already have the song title and album title, so the next step is adding the split!
Let’s start with a reminder of what we are trying to achieve:
The split array would indicate after which indexes there were spaces, in a space-less string of the song title. For example,
“shakeitoff”-> [4,6]because:
Shake it off
01234 56 789
To do that, we will find the first occurrence of space, add it to the split array, remove it, and find the next occurrence, until there are no more spaces.
Note that I’m removing the space that I “checked in” so that we won’t stop on it in the next find. Also, you need to specify you want to replace only 1 occurrence: song_name.replace(" ","",1)
Now, we need to create objects containing the properties we have so far:
I chose to stringify the split array because it would be easier to read later.
Lastly, we call the function in the main code:
...
arr_with_split = create_arr_with_split(song_to_album)
Creating The Data Set
For this to be a legit data set for the Wordle game, we are missing three actions: Shuffle the list, add ids, and save to a file.
- We use an additional variable because
shuffle()is a function that affects the input object. Thereplace()function, for example, did not. This is why we needed to save the modified string:str = str.replace(...) - The use of the function
list(..)is to make the copy deep. Otherwise,shuffledwould’ve pointed at the same array, and usingshuffle(...)would’ve mixed our original list. It won’t be a problem now, but for future functionality, we need to keep the original list as it is. - In the for loop we use
enumerate(..)to get access to the loop index (for i..). - Fun fact: the lists are independent (
arr_with_splitis not shuffled andshuffledis shuffled), but the objects they contain are shared — the newidproperty we added forshuffledappear inarr_with_splitobjects as well!
The last thing left to do is write our data set to a JSON file. I created functions for writing and reading from files. It’s very useful for testing!
That’s it! This is our main.py:
This was intense! We deserve a break!
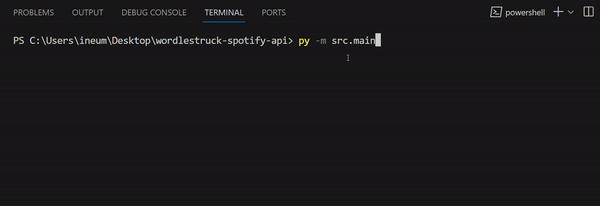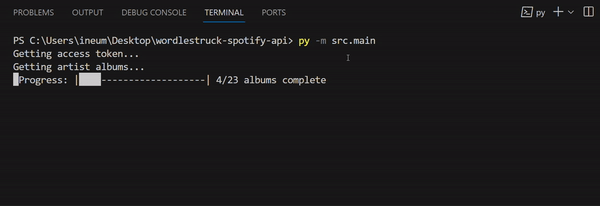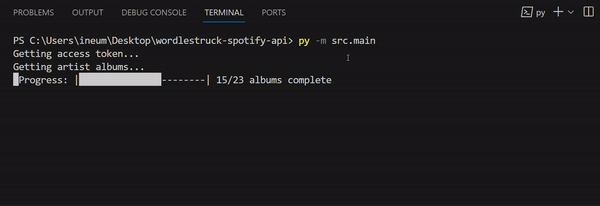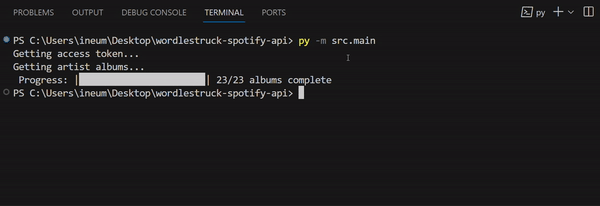
While waiting for my API calls to populate my dictionaries, I thought it would be cool to create a progress bar. I always wondered how the line gets rewritten in the terminal — so this was a good opportunity!

Feature: Progress Bar
Here is what it would look like:
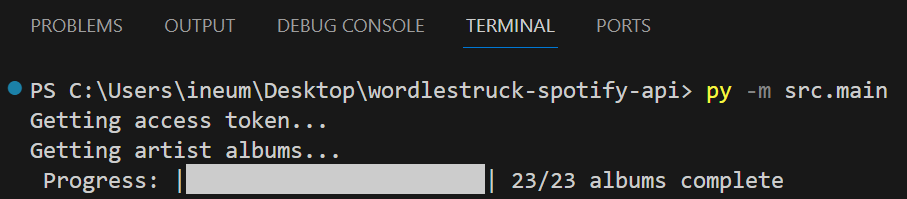
We’ll start with the printing progress function:
- On lines 2–3, I define the characters I’ll use to represent full and empty parts of the bar.
- Line 4 is building the bar: The length of the bar will always be
len_range, and the amount of █ and-are determined byi. printEndneeds to be\rfor the line to override itself in updates, but I added the option\nto wrap it up (wheni==len_range). This is because otherwise the next line I print after gets swallowed by the progress bar.- Lastly, the print. I started with
/rbut that’s a personal preference. The main thing to notice is the structure of the string:'Progress: |%s| %s/%s albums complete' % (bar, i, len_range)
Note that if your terminal window is not wide enough to contain the print in one line — the override won’t work!
Now let’s call it in main:
Note that in line 3 we start the progress bar empty, and inside the for loop (line 9) we call the function with i+1, because the album on index 2 is the 3rd album.
Also, to reach i in the for loop, we iterate over enumerate(album_name_to_id).
Modifications For Future Use
Tay Tay announced she is releasing a new Album on April 19th, and we need to prepare our code for that!
After many trials and errors, I’ve decided to create a new data set on every update. This does not mean I will make all the API calls to Spotify and string processing on every update! You can, it will lead to the same result, but it’s not optimized.
For the updating feature, I will be creating 4 files in the code:
1_album_to_name_id.json
2_song_to_album.json
3_arr_with_split.json
4_dataset.json
After every pull, we save the relevant information, ensuring we execute only the necessary parts. Let’s see it in the code!
Adding External Files
The easy part is to add the write functions:
Note that the file path should be relative to the terminal’s directory! My terminal is open on the project’s main folder so the writing file paths start with src/ !
Soon we will be adding read functionality for those files. It is too easy to update the write file path and forget the read path. Therefore, we will save those as variables:
Now we need to add read-from-files and ensure it works with empty files. What exactly do we want? It’s easier to figure out when we focus on a small group of albums, so we’ll look at the 1989 albums.
The 1989 Test
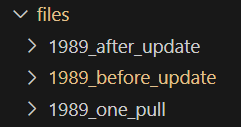
If you look at the list of albums, you’ll see 1989 (Taylor’s version) is the most recent album. I considered the chronological order because I thought of making the actual API call. Then I realized I could just mock it. Anyway, 1989 it is!
We’ll start by modifying album_to_name_id to contain only the original 1989 albums:
# album_name_to_id = create_album_name_to_id_dict(json_result_album_items)
album_name_to_id = {
"1989 (Deluxe)": "1yGbNOtRIgdIiGHOEBaZWf",
"1989": "5fy0X0JmZRZnVa2UEicIOl"
}
Now we’ll execute the program and let it populate our files.
So far so good. Now, let’s mock an update call:
# album_name_to_id = create_album_name_to_id_dict(json_result_album_items)
album_name_to_id = {
"1989 (Taylor's Version) [Deluxe]": "1o59UpKw81iHR0HPiSkJR0",
"1989 (Taylor's Version)": "64LU4c1nfjz1t4VnGhagcg",
}
And think about what we want the program to do.
1_album_name_to_id.jsonshould contain a total of 4 albums. We want to make sure we process only the new albums.2_song_to_album.jsonshould contain an additional 3 songs.3_arr_with_split.jsonshould also contain an additional 3 songs, but we want to ensure we process only those!4_dataset.jsonwill be overridden so no extra action is required from us.
Updating 1_album_name_to_id.json
With the code as it is now, the new album dictionary will override the previous one:
...
json_result_album_items = get_albums(access_token, artist_id, "album")
album_name_to_id = create_album_name_to_id_dict(json_result_album_items)
write_to_json_file(ALBUM_NAME_TO_ID_FILE_PATH, album_name_to_id)
...
So let’s execute the code as usual, but read the previous dictionary and update the variable before writing to the file:
- On line 7 we merge the two
album_name_to_iddictionaries. Note that we updated the new album with the old album so that the list will be LIFO = last in first out. This is critical for assigning the original album to each song. - On line 9 we update the file. Note that this line was originally before the for loop on line 3 but now it is after!
- On line 6 we save the previous object of albums. This requires modifying the read function to accommodate the first execution of the program (when the file doesn’t exist):
Note that with these changes, we only execute the songs section on the new albums!
Updating 2_song_to_album.json
Look at the code as it is now and consider that we want to keep the original album names (and have "Blank Space": "1989" instead of "Blank Space": "1989 (Taylor’s Version)"):
song_to_album = {}
for album_name in album_name_to_id:
...
write_to_json_file(SONG_TO_ALBUM_FILE_PATH, song_to_album)
There are 2 ways to achieve this:
- Let the old dictionary override the new dictionary values:
2. Extract the new songs. This means the second dictionary will only have new keys, and add those to the new list:
We’ll go with option number 2 because it will be useful in the next section!
Updating 3_arr_with_split.json
As a reminder, this is the code as it is now:
...
arr_with_split = create_arr_with_split(song_to_album)
write_to_json_file(ARR_WITH_SPLIT_FILE_PATH, arr_with_split)
shuffled = list(arr_with_split)
...
In this case, the logic will be similar. Just note that this is an array we are updating, so we use the .extend() function instead of .update().
I think it can be confusing to call the updated list “prev”, so I created a new variable:
updated_arr_with_split = list(prev_arr_with_split) # new var for readablity
write_to_json_file(ARR_WITH_SPLIT_FILE_PATH, updated_arr_with_split)
For this to work, we need to modify the read function to be able to return an empty array! The function as it is now returns only an empty dictionary if the file doesn’t exist. This can be achieved by a small tweak:
def from_file_to_json_obj(file_path, array = False):
if Path(file_path).exists():
...
return [] if array else {}
This means that when we read from the array file, we add the array flag:
prev_arr_with_split = from_file_to_json_obj(ARR_WITH_SPLIT_FILE_PATH, array=True)
Now we’ll see it in action!
Here is the updated main file:
There are 3 tests to perform:
-
album_name_to_id = { "1989 (Deluxe)": "1yGbNOtRIgdIiGHOEBaZWf", "1989": "5fy0X0JmZRZnVa2UEicIOl" } -
album_name_to_id = { "1989 (Taylor's Version) [Deluxe]": "1o59UpKw81iHR0HPiSkJR0", "1989 (Taylor's Version)": "64LU4c1nfjz1t4VnGhagcg" } -
album_name_to_id = { "1989 (Taylor's Version) [Deluxe]": "1o59UpKw81iHR0HPiSkJR0", "1989 (Taylor's Version)": "64LU4c1nfjz1t4VnGhagcg", "1989 (Deluxe)": "1yGbNOtRIgdIiGHOEBaZWf", "1989": "5fy0X0JmZRZnVa2UEicIOl" }
We want to start with an empty files directory and run test #1. Then, with those new files, run test #2 and see if the files look as we expected. After that, we want to move those files aside and run test #3 on a clean slate. Lastly, compare those files: This is our one pull vs update test.
Oops
The same thing happened to me again! I was working on this project, listening to Tay Tay (as one does), and I suddenly realized “You’re losing me”, which I’ve been listening to on repeat 1, is not in the data set!
When I started working on this project, I decided to include only the studio albums because the singles list was full of duplicates (Lavander Haze, Anti-Hero, …). Turns out I was too quick to dismiss that album type. Back to the API call!
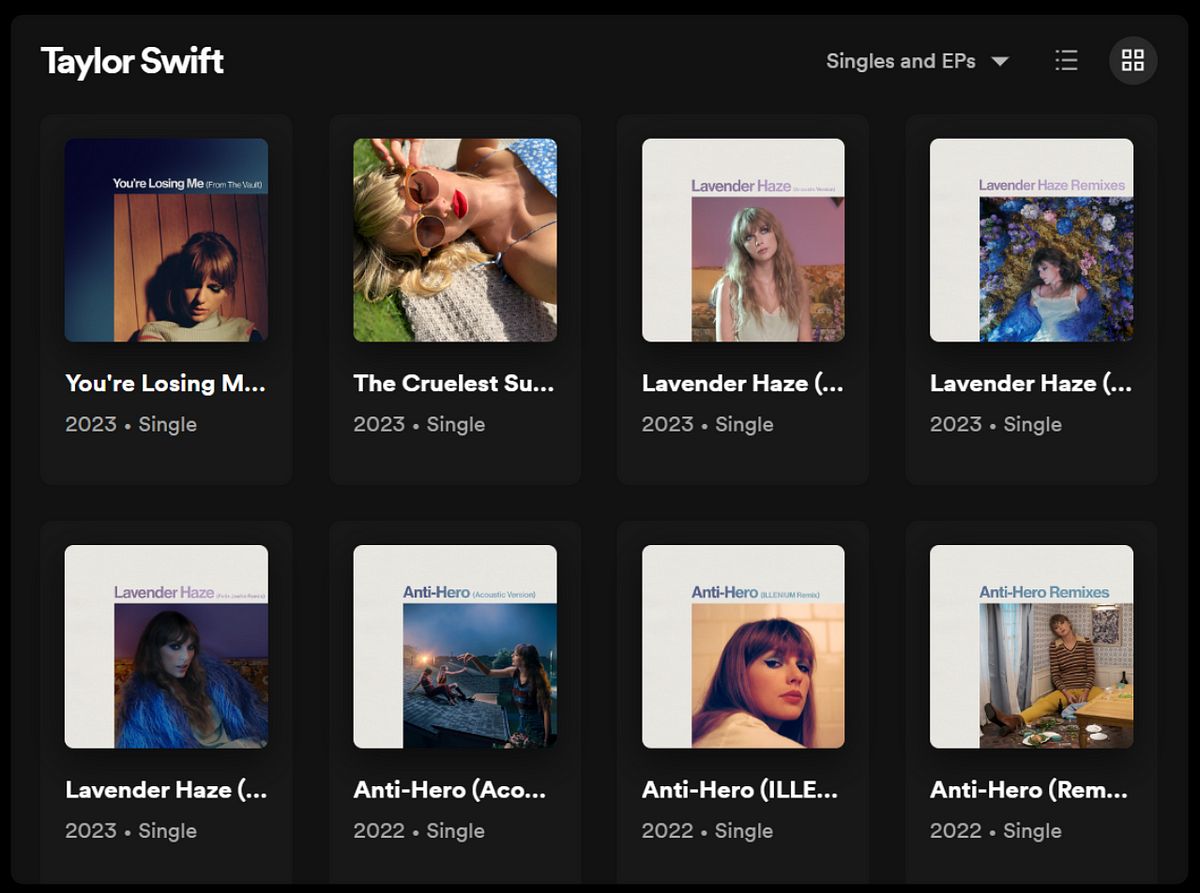
Pulling the single songs
There are two ways to gather the single albums along with the studio albums. One way is to make a single API call with include_groups=album,single. The other way is to make two separate API calls, one for include_groups=album and one for include_groups=single.
I would’ve chosen the first option if the response would’ve brought the albums in chronological order. As it is now, the response contains the studio albums in chronological order, and then the singles in chronological order. I’ve tried sorting them by date but things got messy quickly.
Therefore, I’ll be making two API calls. I will treat the singles API call as an update to the dataset. That way, all the duplicates won’t mess up the song dictionary, and the songs that are only singles will be added.
Nice to meet you, Pagination
If you make the API call with include_groups=single, you will see there is a total of 64 albums. This is above the maximum limit of items in a response — which means we need to paginate!
I didn’t address pagination prior, because we used the API call with the include_groups=albums parameter and the total was 26. This is half of the maximum amount of items coming back in the call (limit=50). Therefore I made the executive decision not to paginate on those.
So, let’s talk about pagination!
If you look at the response JSONs I shared earlier (for the call https://api.spotify.com/v1/artists/06HL4z0CvFAxyc27GXpf02/albums for example), you will see that one of the values in the response is next. This contains the URL to the next page of items (or None if there isn‘t one).
This URL means that not all the data we asked for is coming in one response, and to get the next page of the data, we need to make another API call. The difference between those calls is the offset, which is the first item index appearing in the response.
To make it clear, we’ll change our limit to be 5. With a total of 26 albums, we will need a total of 6 API calls to gather all the albums!
Now, we want at least one call to get albums, and then keep calling until next==None. This is a perfect candidate for a do-while loop, which unfortunately does not exist in Python. I saw online you can create a version of it with While True:...break but it itches me to use While True. And then I had an epiphany: You know what will be fun? RECURSION 😀 Have you done those since your last job interview?
The core of the recursion is to make an API call to the given URL, gather album names, and return that list after we concat that to the list returning from the recursive call.
Our stopping condition will be if url == None.
Let’s see it in the code!
Lastly, the rest of our program doesn’t need to know what is happening under the hood, so we will wrap the call to the function and gather the parameters it needs:
Note that I’m adding a variable for album type, to reuse this function for the two API calls!
This is a good place to add limit as an optional parameter because when we update our dataset we don’t need to pull all the albums, we can take a quick look in Spotify and eyeball estimate the amount.
If we didn’t paginate, limit would’ve worked by itself: One function call – one API call – one response. With recursion, limit is just telling how thin we want the slices. Therefore, we need to add a flag to indicate to our function that we don’t want the other pages!
This is how I implemented this feature:
- On line 9, I added to the function 2 parameters: limit and an optional offset. The offset is for testing.
- On line 14 I created a boolean that is true if the limit is smaller than 50 (which is my program’s default limit).
- In the recursion, on line 4 I check if this is an update call. If it is: I return the items and exit. if not, we continue to the next iteration.
Lastly, we integrate this in the main code:
- I added an optional argument for the limit, which I checked for on line 1.
- If I want to pull the latest 5 albums, I run
py -m src.main 5. - If I need an initial pull, I don’t add anything, and the default is set to 50.
- If I want to pull the latest 5 albums, I run
- On line 5 I pass that variable to
get_albums().
Test your code:
Add an offset to get_albums(..., limit, offset=5), run py -m src.main, remove the offset get_albums(..., limit) and then run py -m src.main 5 – This is a dataset update!
Compare the lists coming back from the update to the lists returning from a single pull. If you are pleased with the result — we can move on!

Merging Singles in The Code
As I mentioned, we will treat this list like an update, and only add the unique keys.
A good way to achieve that is by looping over the album type:
- On line 3 we add a for loop. The loop block contains all the code until the shuffle.
- Now that we have two
album_name_to_iddictionaries. Therefore, we insert thealbum_name_to_id_file_pathvariable inside the loop (line 4).
Skip Albums
We have just a tiny issue to solve before closing this project. As a Swifty, when I look at the songs dictionary I see some strange pairings:
{
"Better Man": "reputation Stadium Tour Surprise Song Playlist",
"Love Story": "Live From Clear Channel Stripped 2008",
"Santa Baby": "The Taylor Swift Holiday Collection",
"September": "Spotify Singles",
"I Want You Back": "Speak Now World Tour Live",
...
}
Better Man should be linked to Red (Taylor’s Version), Love Story is from the Fearless album, and the rest are covers, which might sound nice but are useless in a word game.
These oopsies don’t mean our code is wrong, but some albums will inevitably need to be skipped. In this list belong all the albums that should be ignored completely.
My list is:
How do we add this feature to the code?
We start by reading the file and saving it into a variable. Then, instead of looping over all the albums received from the API call, we filter out the albums that appear in the skip dictionary. Let’s see it in the code:
Note that we still save the full albums dictionary in our files, to keep track of the albums we’ve processed.
After this change, the song dictionary is correct:
{
"Better Man": "Red (Taylor's Version)",
"Love Story": "Fearless (International Version)",
~~"Santa Baby": "The Taylor Swift Holiday Collection",~~
~~"September": "Spotify Singles",~~
~~"I Want You Back": "Speak Now World Tour Live",~~
...
}
Well, almost.
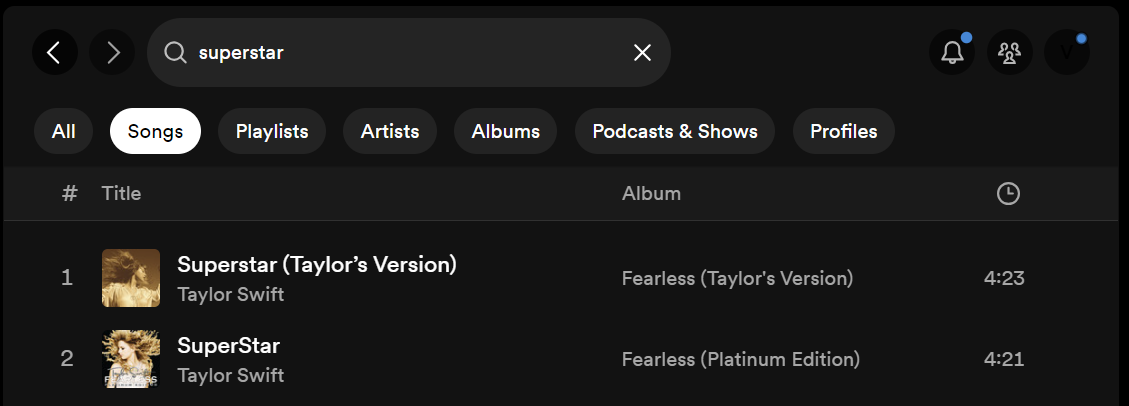
Tay Tay decided to rerecord SuperStar but not keep the original name — which for our dictionary means “new song!”. I can solve it by unifying the dictionary keys — all upper-case or all lower-case.
I decided not to do so because I wanted to preserve the original song titles. Therefore, my game will have 2 occurrences of the song Superstar. I can’t recall the last 5 solution words in Wordle, so hopefully my users won’t notice either 😀
Now we are done!
What a journey! For a second there, I thought this blog post would never end!
Today we learned about OAuth2.0, bearer authentication, and Spotify API. We created API calls, processed data, and created a beautiful clean dataset.
This was the fourth and last part of my Wordle series. See you in the next one!